Performance & Concurrency | Build Fuel Tune
Posted by Simar Paul Singh on 2019-02-26
Performance can be Built, Fueled or Tuned.
Built (Implementation and Techniques)
- Binary Search O(log n) is more efficient than Linear Search O(n)
- Caching can improve Disk I/O significantly boosting performance.
Fuelled (More Resources)
- Simply get a machine with more CPU(s) and Memory if constrained.
- Implement RAID to improve Disk I/O
Tuned (Settings and Configurations)
- Tune Garbage Collection to optimize Java Processes
- Tune Oracle parameters to get optimum database performance
Capacity and Load
Load is an Expectation out of system
- It is the rate of work that we put on the system.
- It is an factor external to the system.
- Load may vary with time and events.
- It has no upper cap, can increase infinitely
Capacity is a Potential of the system
- It is the max rate of work, the system supports efficiently, effectively & infinitely
- It is a factor, internal to the system. Maximum capacity of a system is finite and stays fairly constant. We often call Throughput as the System’s Capacity for Load.
Chemistry between Load & Capacity
- LOAD = CAPACITY? Good Expectation matches the potential. (Unreal)
- LOAD > CAPACITY? Bad Expectations is more than potential. (Reality)
- LOAD < CAPACITY? Ugly Expectations is less than potential. (Waste)
Performance and Capacity Measurement
Response Time or LatencyMeasures of System’s Capacity
- Measures time spent executing a request (Round-trip time (RTT) for a Transaction)
- Good for understanding user experience
- Least scalable, Developers focus on how much time each transaction takes
Throughput
- Measures the number of transactions executed over a period of time (Output Transactions per second (TPS))
- A measure of the system’s capacity for load
- Depending upon the resource type, It could be hit rate (for cache)
Resource Utilization
- Measures the use of a resource (Memory, disk space, CPU, network bandwidth)
- Helpful for system sizing, is generally the easiest measurement to Understand
- Throughput and Response Time can conflict, because resources are limited
- Locking, resource contention, container activity
Handle mismatch between capacity and load (Throttling & Buffering Techniques)
No one stops us to load a system more than its capacity (Max Throughput).
Transactions Per Seconds -Misconception, Real traffic may be in bursts
- Received 3600 transactions in a hour, not sure if every second only 60 were pumped
- Probably we received in bursts — all in first 10 minutes and for nothing last 50 minutes
- So we really cant say, at what tps? We can regulate bursts with throttling and buffering
Throttling — (Implemented by producer to smoothen output)
- Spreads bursts over time to smoothen output from a process
- We may add throttles to control output rate from threads to each external interface Throttle of 10 tps ensures max output is 10 tps regardless of the load & capacity. Throttling is scheme for producers ( Check production to rate the consumer can accept)
Buffering — (Implemented by consumer to smoothen input)
- Spreads burst over time to smoothen input from an external interface
- We add buffering to control input rate to threads from each external interface Application processes input at 10 tps, load above it will be buffered & processed later Buffering is a scheme for consumers (Take whatever is produced, consume at our own)^
Supply Chain Principle (Apply it to define a optimum Thread Pool Size)
Thread is an abstract CPU unit resource here.
The more throughput you want, more will be the resource consumption.
You may apply this principle to define the optimum thread-pool size for a system/application.
— To support a Throughput (t) transactions per second- (t) = 20 tps
— Where each transaction takes (d) seconds to complete- (d) = 5 seconds
— We need (dt) threads at least (min size of the thread pool)- (dt) = 100 threads
To support a Throughput (t) of 20 tps Where each transaction takes(d) 5 seconds We need 100 (d*t) threads at least
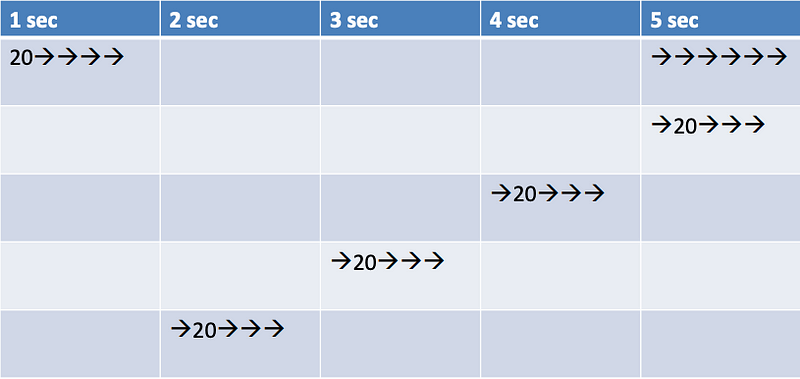
100 threads kept busy executing 5 batches of 20 (100 transactions) where each takes 5 seconds to complete ( A batch of 20 coming in and leaving every second)
Quantify Resource Consumption
Utilization & Saturation
Resource Utilization
- Utilization measures how busy a resource is.
Resource Saturation
- Saturation is often a measure of work that has queued waiting for the resource
- It can be measured as both
- As an average over time
For some resources that do not queue, saturation may be synthesized by error counts. Example Page-Faults reveal memory saturation.
Load (input rate of requests) is an independent/external variable, user of a system can at any point be overloading or under consuming the system.
Resource consumption, Throughput (out-put rate of response) are a function of load and dependent on internal variables (threads for cpu, queues for memory)
How Load, Resource Consumption and
Throughput related?
- As load increases, throughput increases, until maximum resource utilization on the bottleneck device is reached. At this point, maximum possible throughput is reached, Saturation occurs.
- Then, queuing (waiting for saturated resources) starts to occur.
- Queuing typically manifests itself by degradation in response times.
- This phenomenon is described by Little’s Law:
L = X * R
L (LOAD), X (THROUGHPUT) and R (RESPONSE TIME)
- As L increases, X increases (R also increases slightly, because there is always some level of contention at the component level).
- At some point, X reaches Xmax — the maximum throughput of the system. At this point, as L continues to increase, the response time R increases in proportion and through-put may then start to decrease, both due to resource contention.
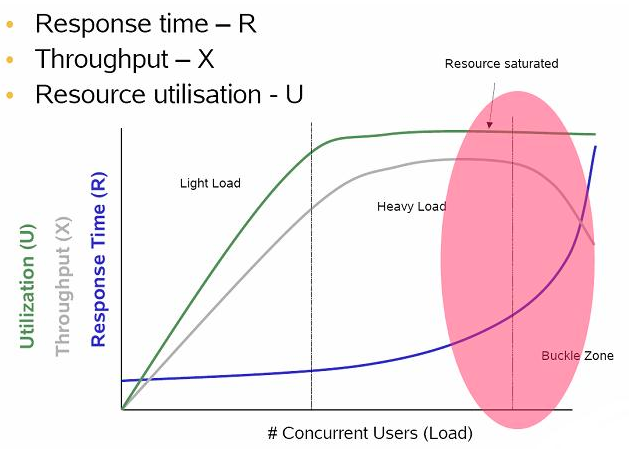
Performance pattern of a Concurrent Process
How Throughput and Resource Consumption are related? (Example)
Throughput & Latency can have an inverse or direct relationship. Concurrent tasks (Threads) often contend for resources (locking & contention)
Single-Threaded — Higher Throughput = Lower Latency
- Consistent throughput, does not increase with incoming load & resources
- Processes serially, Good for batch jobs
- Response Time linearly varies with request order.
Multi-Threaded — Higher Throughput = Higher Latency (Most of the time)
- Throughput may increase linearly with load, it starts to drop after threshold
- Process Concurrently, Good for interactive modules (Web Apps)
- Near consistent Response Time, doesn’t vary much with order but load. Single Threaded — 10 CPU(s) Multi Threaded — 10 CPU(s) Threads = 1 Latency = .1 seconds Throughput = 1/.1 = 10 tx/sec
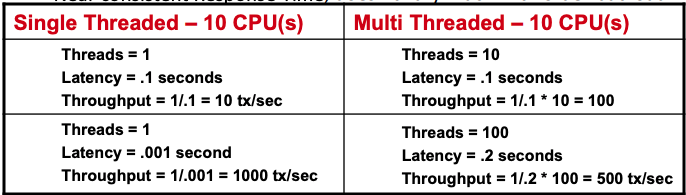
Non linear vertical scaling with threads due to cpu latency from context switching
Producer Consumer Principle
- The Utilization Law: Ui = T * Di
- Where Ui is the percentage of utilization of a device in the application, T is the application throughput, and Di is the service demand of the application device.
- The maximum throughput of an application Tmax is limited by the maximum service demand of all of the devices in the application.
- EXAMPLE — A load test reports 200 kb/sec average throughput:
CPUavg = 80% | Dcpu = 0.8 / 200 kb/sec = 0.004 sec/kb
Memoryavg = 30% | Dmemory = 0.3 / 200 kb/sec = 0.0015 sec/kb
Diskavg = 8% | Ddisk = 0.08 / 200 kb/sec = 0.0004 sec/kb
Network I/Oavg = 40% | Dnetwork I/O = 0.4 / 200 kb/sec = 0.002 sec/kb
- In this case, Dmax corresponds to the CPU. So, the CPU is the bottleneck device.
- We can use this to predict the maximum throughput of the application by setting the CPU utilization to 100% and dividing by Dcpu. In other words, for this example: Tmax = 1 / Dcpu = 250 kb/sec
- In order to increase the capacity of this application, it would first be necessary to increase CPU capacity. Increasing memory, network capacity or disk capacity would have little or no effect on performance until after CPU capacity has been increased sufficiently.
Work Pools (Queues) & Thread Pools Working Together
Work Pools are queues of work to be performed by a software application or component.
- If all threads in thread pool are busy, incoming work can be queued in work pool
- Threads from thread pool, when freed can execute them later
Work Pools cover up congestion & smoothen bursts
- A queue consisting of units of work to be performed
- CONGESTION, by allowing the current (client) threads to submit work and return
- BURST, over capacity transaction can buffered in work pool and executed later
- Allow for caching of units of work to reduce system intensive calls —( Ex. we can perform a bulk fetch form a database instead of fetching on record at a time)
Queuing Tasks may be risky
- One task could lock up another that would be able to continue if the queued task were to run.
- Queuing can smoothen in-coming traffic burst limited in time (depending upon the rate of traffic and size)
- Fails if traffic arrives on average faster than they can be processed.
- In general, Work Pools are in memory so it is important to understand what the impact of restarting a system is, as in memory elements will be lost.
Bounded & Unbounded Pools (Load Shedding)
If not bounded, pools can grow freely but can cause system to exhaust resources.
- Work Pool / Queue Unbounded — (May overload Memory / Heap & crash) — Each work object in the queue stays holding the space until consumed
- Thread Pool Unbounded — (May overload CPU / Native Space and Crash) — Each thread asks to be scheduled on CPU and consumes native stack space
If queue size is bounded, incoming execute requests block when it is full. We can apply different Policies to handle t, for example
— Reject if there is no space (Can have side affects)
— Remove based on Priority — (Ex priority may be function of time — Timeouts)
Thread Pools can have different policies when Work Pools is full:
- Block till there is available space — Starve (VERY BAD — Sometimes Needed)
- Run in Current Thread (Very Dangerous!)
Work pool & thread pool sizes can often be traded off for each other
Large Work-Pool and small thread pools
- Minimizes CPU usage, OS resources, and context-switching overhead.
- Can lead to artificially low throughput especially if tasks frequently block (ex I/O bound)
Small Work pool generally require larger thread pool sizes
- Keeps CPUs busier
- May cause scheduling overhead (Context Switching) and may lessen throughput. Especially if the number of CPUs are less.
This article is also aviable on my Medium publication. If you like the artile, or have any comments and suggestions, please clap or leave comments on Medium.